Using Twitter replies as blog comments
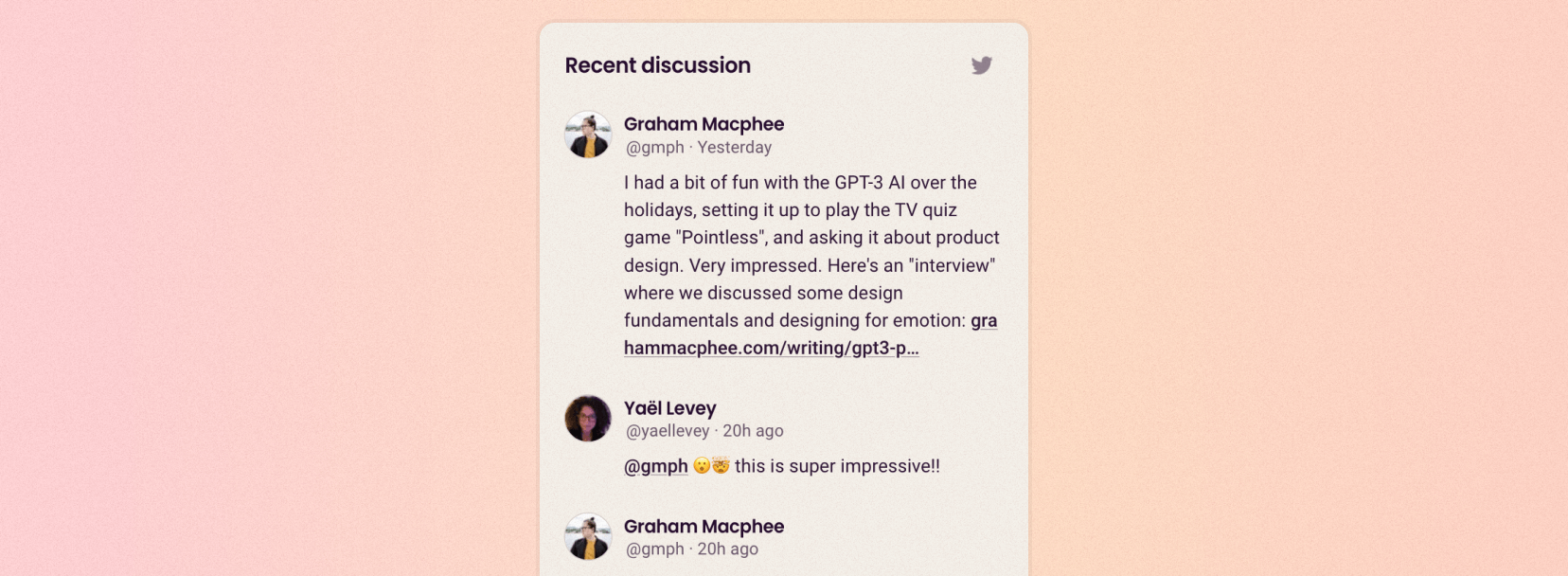
While working on my website, I've taken some time to make it easier for people to engage in discussions with me. Most discussions I have about my articles happen on Twitter, so I've built a way to see recent conversations from Twitter when viewing articles on my website.
Here's how it works:
- On my website, at the bottom of each article, I built a way to display relevant conversation from Twitter and a link to join that conversation on Twitter.
- On the server, I built an endpoint to fetch relevant tweets for an article. This uses the search function of the Twitter API to find tweets that link to the article and replies to those tweets.
- In my article editor, I added a way to manually link tweets that are relevant to each article. This is useful if there are interesting conversations without a direct link to the article.
Client implementation
Let's start with the client code, which you can see in action at the bottom of this article if you're viewing it on my website.
The tools and frameworks I use for my website, and for this interface for displaying tweets, are Netlify CMS, Next.js, React and TypeScript.
The client needs to load tweets that are relevant to the current blog post, then display them. It does this by querying my server with the path of this blog post, plus some manually added tweet ids. When the tweets are returned, they are stored in the React component's state. Finally, the tweets are rendered. If there are no tweets, an empty state is displayed instead.
The client also needs a link to the conversation on Twitter so the viewer can click to reply to the discussion. To do this, a link is generated based on the conversation_ids provided by the server. As a fallback, the button will link to my profile.
Here's a simple version of the React component:
function Conversation({ path, ids }: Props) {
const [replies, setReplies] = useState([]);
const [conversationIds, setConversationIds] = useState(ids || []);
useEffect(() => {
getConversations({ path, ids }, conversations => {
setConversationIds(conversations.conversation_ids);
setReplies(conversations.replies);
});
}, [path, ids]);
const primaryTwitterLink = 'https://twitter.com/gmph' +
(conversationIds && conversationIds.length ? '/status/' + conversationIds[0] : '');
return (
<aside>
<h3>{replies.length ? 'Recent discussion' : 'No recent discussion'}</h3>
{!replies.length ? <>
<p>Tweet @gmph and link to this article to see your tweet featured here.</p>
</> : null}
{replies.map((reply: TwitterStatus) =>
<Tweet key={reply.id_str} {...reply} />
)}
<Button href={primaryTwitterLink}>Reply on Twitter</Button>
</aside>
);
}
Server implementation
Now that we know how the client code works, we can look at the server side in more detail. This is what happens on the server when it receives a request for relevant tweets:
First, it gets a set of tweets I define manually for each blog post (e.g. my own tweet sharing the post). Then, it gets other relevant tweets that include the blog post URL via the Twitter search API (the search/tweets endpoint). Once it has all these tweets, it gets all the recent replies to them, again using Twitter search API. Finally, it returns all of these tweets and replies to the client.
Here's an abridged version of the server code for this endpoint:
const handler: Handler = async (request) => {
const conversationIds = request.queryStringParameters['ids'];
const path = request.queryStringParameters['path'];
try {
const knownTweetIds = conversationIds ? conversationIds.split(',') : [];
const knownTweets = await getTweetsByIds(knownTweetIds);
const relevantTweets = await getRelevantTweetsForPath(path);
const relevantTweetIds = relevantTweets.map(tweet => tweet.id_str);
const tweetReplies = (await Promise.all(
[...knownTweetIds, ...relevantTweetIds].map(id => getTweetReplies(id))
)).flat();
return {
statusCode: 200,
body: JSON.stringify({
conversation_ids: [...knownTweetIds, ...relevantTweetIds],
replies: getSanitizedTweets([
...knownTweets,
...relevantTweets,
...tweetReplies
]),
}),
};
} catch (error) {
return getError(error);
};
}
Each of the calls to get tweets will make a request to the Twitter API. For example, the getTweetReplies function queries the search/tweets endpoint using a conversation_id. It looks something like this:
function getTweetReplies(conversationId: string): Promise<any[]> {
// GET request to https://api.twitter.com/1.1/search/tweets.json
return twitterGet("search/tweets", {
q: `conversation_id:${conversationId}`,
tweet_mode: 'extended',
}).then((result) => {
return result.statuses;
});
}
For my site, this server code is hosted as a serverless function using Netlify. I used the unofficial twitter library for JavaScript, wrapped in my own error handling code.
Safety and security
I took a few precautions to avoid negative experiences with this implementation.
- Restricting to my username and domain – I hardcoded the server code to sanitise inputs and limit results to those linked to my website and my Twitter username. This ensures the endpoint isn't generally useful, removing the incentive for people to use it themselves.
- Filtering out tweets from private accounts – The Twitter API uses my user credentials to query Twitter, meaning raw results may include tweets from people with private (
protected) accounts if I follow them. I remove these tweets to ensure private content from Twitter is never exposed publicly. - Filtering out sensitive content – The Twitter API annotates tweets that may include unsafe content. I filter out
possibly_sensitivetweets from the responses returned. I also prevent rendering of links in anypossibly_sensitivetweets if they are received by the client. - Caching responses – Rate limits apply to the Twitter API endpoints. If the Twitter API was called every time a person viewed a page on my website, it wouldn't scale to support a high level of traffic. To reduce the impact of this, I cache responses on the server and cache data on the client.
Limitations
- Recent tweets only – Standard search in the Twitter API is limited to recent tweets from the past 7 days. This means finding older discussions isn't possible, so the discussion displayed may be limited. To overcome this, I would need to have my app approved for the Premium API.
- No threading – Right now, my client code renders tweets in a flat list, meaning it doesn't chain replies into threads. This is something I would improve if I expected longer/complex conversations to happen around my articles. Threads could be composed using the
in_reply_to_id_strfield returned for each tweet from the Twitter API.
Feedback
If you have any feedback on this implementation or you're working on something similar, I'd love to hear from you. You can reply to me on Twitter below 😉
Have a lovely day.
© 2026, Graham Macphee.